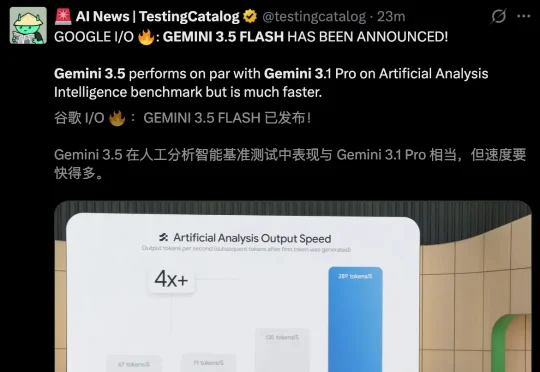
Gemini 3.5来了!今夜,谷歌亲手淘汰谷歌
Gemini 3.5来了!今夜,谷歌亲手淘汰谷歌劈柴和Hassabis把半年大招一晚清仓了!Gemini Omni任意输入生成视频,3.5 Flash断层碾压一切,Spark 7×24h云端替你干活。这次,谷歌是要把OpenAI和Anthropic一起给埋了。
来自主题: AI资讯
8955 点击 2026-05-20 09:13
 搜索
搜索
劈柴和Hassabis把半年大招一晚清仓了!Gemini Omni任意输入生成视频,3.5 Flash断层碾压一切,Spark 7×24h云端替你干活。这次,谷歌是要把OpenAI和Anthropic一起给埋了。
发布会还没开,谷歌彻底藏不住了!Gemini 3.2 Flash网页端静默上线,被开发者抓了个正着。单次提示狂飙2200行代码、手搓Windows 98,直接把自家旗舰Pro按在地上摩擦。

无论最终叫Veo 4还是Gemini Omni,这次泄露已足够震撼:AI视频不再是短视频工具,而是拥有导演思维的叙事生产力。谷歌I/O当天,答案即将揭晓,而整个行业,都将重新洗牌。
就在刚刚,Gemini 3.5提前曝光了! 网友Lentils放出最新消息,代号「Cappuccino」的Gemini 3.5 Pro检查点已经开始产出。而就在几个小时前,传闻还是Gemini 3.2,没想到一下子就替换成了Gemini 3.5。

2026年5月13日,作为每年 Google I/O 的前哨站,同时也是关于最重要的部分——安卓的独立发布会,The Android Show在线上开幕,揭开了 2026 年 Google 在 Android 领域全系产品阵容的新品发布阵容。

今天,谷歌原生视频模型Gemini Omni意外曝光!各种惊艳demo刷爆,教授黑板推导数学公式、一句话编辑视频,丝滑程度让全网破防。

他人生最大的一次跨步是博士毕业,毅然决然离开深造9年的物理,来到崭新的AI行业。过去两年,他先后在Anthropic和Google DeepMind出任研究科学家,参与了Claude 3.7、4.5、Gemini 3等关键模型的开发过程。

Chrome正在把你的电脑变成它的AI算力节点,没问过你,没通知你,而且删了还会自动重下。

SWE-Bench 的创建者,刚刚又放出了一个地狱级新 benchmark。
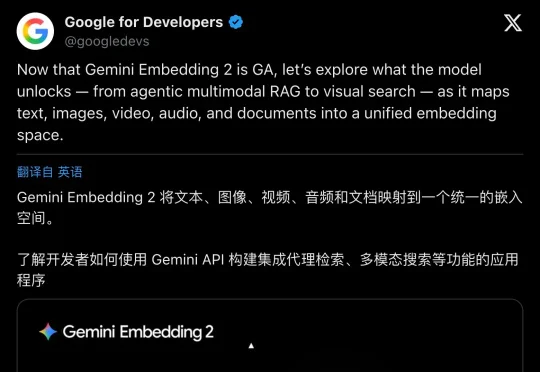
Google悄悄干了一件大事——Gemini Embedding 2正式进入GA阶段,成为Gemini API中第一个原生多模态embedding模型。它能把文本、图片、视频、音频、PDF文档全部映射进同一个统一向量空间,支持100多种语言。